






芯片资讯
热点资讯
- 泽润新能创业板IPO计划募资7.2亿元
- 一文解析Armv8.5-A内存标记扩展(MTE)
- 2024年日本半导体制造商将新建晶圆制造工厂
- 一加 Ace 3 获南德 48 个月 A 级流畅认证,全面革新流畅体验
- 工业控制芯片采购指南:高效选型与供应链优化
- 国产芯片MCU极海推出APM32F035电机控制专用 MCU无电解电容变频控制方案
- 苹果连续互通功能:实现多设备间无缝复制粘贴,提升工作效率
- 广汽能源加速充电换电布局,2024年实现"万桩计划"
- 国产射频直采 ADC 再破纪录!成都华微推出首颗 4 通道 40GSPS 芯片,性能达国际领先
- 亿配芯城(ICGOODFIND)2025国庆节、中秋节放假安排
- 发布日期:2024-01-09 12:43 点击次数:214
Perface
摘要——1988年的互联网蠕虫病毒夺走了雏形网络的十分之一,并严重地减慢了剩余网络的速度[1]。30多年过去了,用类C语言编写的代码中最重要的两类安全漏洞仍然是对内存安全的侵犯。
根据2019年的BlueHat演示文稿,微软产品中解决的所有安全问题中,有70%是由违反内存安全造成的[2]。Google也报告了Android的类似数据,超过75%的漏洞是违反内存安全的【3】。虽然这些违规中的许多在较新的语言中是不可能的,但用C和C++编写的在用代码的基础是庞大的。仅Debian Linux就包含了超过5亿行。
本文介绍了Armv8.5-A内存标记扩展(MTE)。MTE的目标是提高用不安全语言编写的代码的内存安全性,而不需要更改源代码,在某些情况下,也不需要重新编译。对内存安全违规的可轻松部署的检测和缓解措施可以防止一大类安全漏洞被利用。
简介
内存安全的破坏分为两大类:空间安全和时间安全。
可利用的违规行为是攻击的第一阶段,旨在传送恶意负载或与其他类型的漏洞链接,以获得系统控制权或泄漏特权信息。
当访问对象超出其真实边界时,空间安全就会受到侵犯。例如,当栈上的缓冲区溢出时。这可能会被利用来覆盖函数的返回地址,这可能会成为几种类型攻击的基础。
当对对象的引用超出范围使用时,通常是在对象的内存被重新分配之后,就违反了时间安全性。例如,当包含某种类型的函数指针的类型被恶意数据覆盖时,恶意数据也可以构成多种攻击的基础。
MTE提供了一种机制来检测两类主要的内存安全违规。MTE通过提高测试和Fuzzing的有效性来帮助在部署之前检测潜在的漏洞。MTE还可以在部署后帮助大规模检测漏洞。
Fuzzing是一种软件测试技术,也称为模糊测试。它通过向软件系统输入大量随机、无效或异常的数据,来检测系统在处理这些数据时是否会出现异常或崩溃。Fuzzing可以帮助发现软件系统中的漏洞和安全问题,从而提高软件系统的稳定性和安全性。
通过仔细的软件设计,可以始终检测到在真正边界之前或之后立即访问内存的顺序安全违规。可以概率地检测到地址空间中任意位置的“野生”违规。
在部署之前定位和修复漏洞,减少了部署代码的攻击面。在部署后大规模检测漏洞,支持在漏洞被广泛利用之前被动地修复漏洞。对网络犯罪经济学的研究【5】表明它对规模非常敏感。及时的检测和被动的修补可能在大规模打击网络犯罪方面非常有效。
威胁模型
MTE旨在提供鲁棒性,以抵御试图破坏代码处理攻击者提供的恶意数据的攻击。它不解决算法漏洞或恶意软件。
MTE旨在检测内存安全违规,并提高针对违规所导致的攻击的鲁棒性。在动态链接系统中,遗留代码受益于MTE的堆分配,而无需重新编译。
将MTE应用到堆栈需要重新编译。MTE架构设计时,假设堆栈指针是可信的。因此,在为堆栈分配部署MTE时,将MTE与其他功能(例如分支目标识别(BTI)和指针验证码(PAC))结合使用非常重要,以降低存在允许攻击者控制的小工具的可能性的堆栈指针。
MTE的内存安全
Arm内存标记扩展实现了对内存的锁定和键访问。可以在内存上设置锁,在内存访问时提供键。如果密钥与锁匹配,则允许访问。如果不匹配,则会报错。
通过在物理内存的每16字节中添加4位元数据来标记内存位置。这就是标签颗粒。标记内存实现了锁。
指针和虚拟地址都被修改为包含键。
为了在不需要更大指针的情况下实现密钥位,MTE使用了Armv8-A架构的Top Byte Ignore (TBI)特性。当启用TBI时,当将虚拟地址的最高字节用作地址转换的输入时,将忽略它。这允许顶部字节存储元数据。在MTE中,最高字节的4位用于提供密钥。
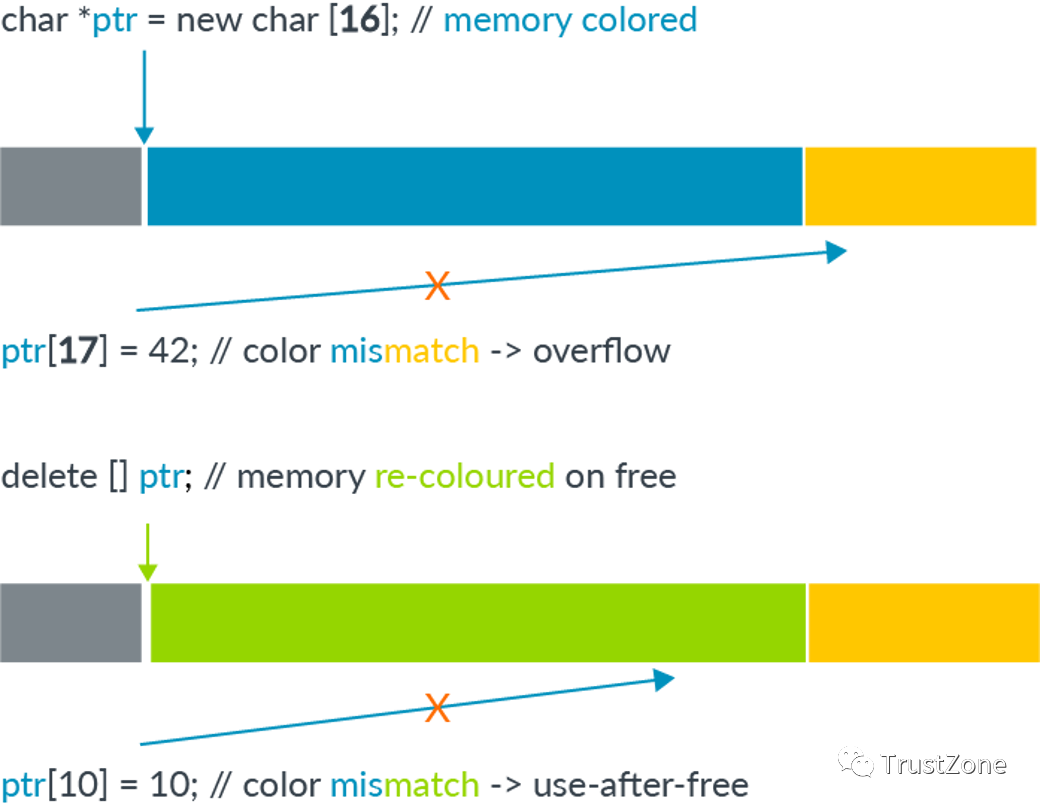
MTE依赖于锁和密钥的不同来检测内存安全违规。
由于可用的标记位数有限,因此不能保证两次内存分配对于任何特定的执行都具有不同的标记。但是,内存分配器可以确保顺序分配的标记总是不同的,从而确保总是检测到最常见的安全违规类型。
更普遍的是,MTE支持随机标签生成和基于种子的伪随机标签生成。在一个程序的执行次数足够多的情况下,其中至少一个程序检测到违规的概率趋于100%。
架构细节
MTE在Arm架构中增加了一种新的内存类型,即Normal Tagged Memory。
除了一些例外,如果可以静态地确定访问的安全性,加载和存储到这个新的存储器类型执行访问,其中地址寄存器顶部字节中的标记与存储在存储器中的标记进行比较。
当不匹配配置为异步上报时,详细信息将累积在系统寄存器中。提供了一个控制,以确保在进入以更高的异常级别运行的软件时更新此寄存器。这使得操作系统内核能够将不匹配的情况隔离到特定的执行线程,并基于这些信息做出决策。
同步异常的精确性在于,可以精确地确定是哪个加载或存储指令导致了标记不匹配。相反,异步报告是不精确的,因为它只能将不匹配隔离到特定的执行线程。
MTE为Armv8-A架构添加了以下概述的说明,并将其分为三个不同的类别【6】:
适用于栈和堆标记的标记操作说明。
•IRG 为了使MTE的统计基础有效,需要一个随机标签的来源。IRG被定义为在硬件中提供此标记,并将这样的标记插入到寄存器中,以供其他指令使用。•GMI 此指令用于操作排除的标记集,以便与IRG指令一起使用。这适用于软件为特殊目的使用特定标记值,同时为正常分配保留随机标记行为的情况。•LDG、STG、STZG 这些指令允许在内存中获取或设置标记。它们的目的是在不修改数据或将数据归零的情况下更改内存中的标记。•ST2G和STZ2G 这些是STG和STZG的更密集的替代方案,它们在分配大小允许的情况下在两个内存颗粒上运行。•STGP 该指令将标记和数据都存储到内存中。
用于指针算术和堆栈标记的指令:
•ADDG和SUBG 这些是ADD和SUB指令的变体,旨在对地址进行算术运算。它们允许标记和地址都被一个立即值单独修改。这些指令用于创建堆栈上对象的地址。•SUBP(S) 此指令提供了一个56位减法,带有可选的标志设置,MACOM射频微波IC芯片 这是指针运算所必需的,忽略顶部字节中的标记。
系统使用说明:
•LDGM、STGM和STZGM 这些是在EL0处未定义的批量标签操作指令。它们旨在供系统软件为了初始化和序列化的目的来操作标记。例如,它们可以用于实现将标记的内存交换到不识别标记的介质。清零形式可以用于高效的内存初始化。此外,MTE还提供了一组设计用于标签的缓存维护操作。这些提供了在整个缓存行上运行的高效机制。
MTE规模部署
Arm预计,在产品开发和部署的不同阶段,MTE将部署在不同的配置中。
精确的检查旨在提供有关故障位置的最多信息。不精确的检查旨在实现更高的性能。
操作系统内核可以选择是否终止由于标记不匹配而导致异常的进程,或者记录该异常的发生并允许进程继续进行。
在启用MTE的情况下测试产品可以发现它的许多潜在问题。在这个阶段,检测和记录尽可能多的问题的信息是合适的。
不需要保护系统免受攻击者的攻击。可能需要将系统配置为:
•进行精准检查。•累积标记不匹配的数据,而不是终止进程。这种配置允许收集最多信息,以支持通过定向测试和Fuzzing找到最大数量的缺陷。
发布产品后,可能需要将MTE配置为:
•执行不精确的检查。•在标记不匹配时终止进程。
此配置在性能和检测可能启动针对软件的漏洞的内存安全违规之间提供了一种平衡。
在发布后,配置对黑客具有高价值的进程(例如加密密钥存储)可能是合适的,以执行精确的检查,以便有关检查失败位置的准确信息可以通过错误报告和遥测系统传回其开发人员。
系统自适应地改变其MTE配置也可能是合适的。
例如,如果使用不精确检查运行的进程因为标记检查失败而终止,那么下次启动该进程时,它可能会从启用精确检查开始,以便为其开发人员收集更好的诊断信息。这种部署模型融合了不精确检查的性能优势和精确检查的优势,以提供更好的质量反馈。
MTE硬件部署
为了支持实现MTE的未来Arm产品,正在开发一个新版本的AMBA 5相干集线器接口(CHI)规范,该规范支持MTE的传输和相干性要求【7】。
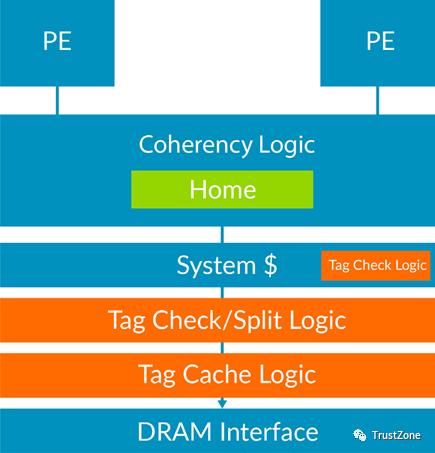
堆标记
在动态链接系统中,可以在不改变现有二进制文件的情况下部署标记堆。只需要修改操作系统内核和C库代码。
Arm通过添加对Linux内核的支持,对MTE进行原型化。需要修改的区域如下:
•能够在使用用户空间指针时将标记从它们中删除用于地址空间管理。•使虚拟内存系统中的clear_page和copy_page函数感知标签。•增加标签不匹配导致的故障处理。类似于SIGSEGV处理翻译故障的方式。•转换可能暴露给用户空间的内存映射进程来使用普通标记内存。•增加扩展检测和系统寄存器配置以启用扩展。
Arm正在向上游贡献Linux内核支持。
在C库中,Arm修改了这些与内存相关的函数:
•malloc•free•calloc•realloc
此外,还修改了内存拷贝和字符串相关函数,以防止它们过度读取源缓冲区。
堆栈标记
在运行时堆栈上分配的内存需要编译器支持和内核支持。二进制文件必须重新编译。可以使用许多不同的堆栈标记策略。
我们的合作伙伴利用IRG设计了一个随机选择标签的策略指令,在函数进入期间,分配一个新的栈帧。然后,编译器使用ADDG和SUBG指令为函数内的每个栈槽创建标记地址,其中标记从初始随机标记偏移。堆栈分配可以使用适当的标记存储指令进行批量初始化,但编译器不需要在函数体代码使用之前初始化任何插槽。
此策略确保MTE的统计属性对于每个函数调用都有效,并确保堆栈上相邻的对象具有不同的标记,从而导致顺序上溢和下溢。
保护堆栈上的相邻对象需要增加这些对象与标记颗粒的对齐,即16字节。在某些程序中,MTE会因为这个效应而导致堆栈使用率增加。我们的基准分析表明,涨幅通常不大。
为了提高性能,在MTE下取消检查使用堆栈指针寻址模式的立即偏移量的内存访问。这是因为编译器可以静态地证明它们是正确的,或者在编译时发出诊断。
MTE优化
MTE的设计使得它不需要修改源代码就可以纠正代码。但是,MTE必然会带来开销,因为标记必须从内存系统中获取并存储到内存系统中。这种开销与内存分配的大小和生存期以及标记和数据是一起操作还是分开操作有关。可以通过以下方式最大限度地减少开销:
•同时写标签和初始化内存。在许多情况下,内存必须初始化为零,并设置标记。例如,在将页面交给用户空间之前,清除操作系统内核中的页面。Arm基于Linux的原型机为此使用了STZGM指令。•避免过度分配从未向其写入数据的地址空间。在某些情况下,软件分配的地址空间远比它所需的多,并且在解除分配之前只接触其中的一小部分。使用MTE,这更昂贵,因为即使数据永远不会写入内存,标记也可能需要。•避免过度的去分配和再分配。避免过多的去分配和再分配通常是一个好的实践,无论是否部署了MTE。但是,由于使用MTE分配和解除分配的固定成本会增加,现有的性能问题可能会被放大。•避免在堆栈上进行大的固定大小分配。堆栈上的大的、固定大小的分配往往会被使用不足,例如,PATH_MAX等固定大小的缓冲区通常包含相对较短的字符串。避免这样的分配,通过减少必须写入的未使用的内存标记的数量,减少了保护堆栈的开销。
参考文献
•[1] F. B. I. [Online]。 Available: https://www.fbi.gov/news/stories/morris worm-30- years-since-first-major-attack-on-internet-110218
•[2] M. Miller, “Bluehat Abstracts,” [Online]。 Available: https://msrnd-cdn-stor. azureedge.net/bluehat/bluehatil/2019/assets/doc/Trends, Challenges, and Strategic Shifts in the Software Vulnerability Mitigation Landscape.pdf
•[3] “Google Queue Hardening,” [Online]。 Available: https://security.googleblog. com/2019/05/queue-hardening-enhancements.html
•[4] Debian, “Stretch Statistics,” [Online]。 Available: https://sources.debian.org/stats/ stretch
•[5] “ACM,” [Online]。 Available: https://dl.acm.org/citation.cfm?id=2654847
•[6] “AArch64 Instructions,” [Online]。 Available: https://developer.arm.com/docs/ ddi0596/latest/base-instructions-alphabetic-order
•[7] “Architecture Reference Manual,” [Online]。 Available: https://developer.arm.com/ docs/ddi0487/lates
编辑:黄飞
- 瑞芯微 RK3588 与即将量产的新旗舰芯片 RK3688 对比解析2025-09-29
- PCBA:电子产品的核心与制造流程解析2025-08-27
- Cyclone系列FPGA:高性能可编程逻辑解决方案的技术解析与应用场景2025-08-25
- 亿配芯城为大家介绍博通 (Broadcom) 芯片产品系列及料号解析2025-08-04
- 电子电路元器件套装与原理图解析:芯片分销商模式如何赋能电子设计2025-05-06
- 一文教会你固定ElfBoard开发板CPU的频率!2024-01-09